摘要
新的西门子言语环向追踪,包含相反方向性极性图,是用来增加在言语并非来自前方时聆听环境下的言语理解度。两个独立的临床试验将言语环向追踪和两个可更换的方向性选择进行比较:全向性和自适应指向性。这个研究表明言语环向追踪在有背景噪声时在言语理解方面具有很重大的优势。这个文章解释了言语环向追踪的工作原理,提供言语环向追踪的行为研究细节以及在Connexx软件中如何验配并且论证了言
语环向追踪。
介绍
自从1960年代后期起,麦克风方向性技术就在助听器中使用,并且显示了能在有背景噪声环境下,言语理解度得到有效地提高。多年以来,这个技术被认为是个“特殊特征”,并且只能使用在精选的模型中。所有的这些都在最近的16-20年得到改变,并且现在的助听器制造商在他们大部分的助听a产品中都提供了方向性技术。
在现代的助听a中,方向性技术在使用两个全向性麦克风时才起效,并且西门子是在1997年首次引入具有双一指向性麦克风助听器(双麦)。对这个新技术的研究显示了令人鼓舞的结果。在2002年,西门子又首次为麦克风方向性极性图增加了自动自适应功能。自动意味着建立在环境监测系统的分析结果,运算法则“自动地”从全向性至指向性问转换,或者从指向性返回全向性。“自适应”指的是指向性集中在前方,但是无效的极性图能在后面的半球面内和最响的声音相匹配,这个能最大限度地削弱在这个区域内的背景噪音。或者,如果探测到是个散发性的噪音场所,自适应运算法则将会选择指向性最好的极性图。
在2004年这个自适应功能被扩展成多通道功能,换句话说,最大的方向性衰减可在不同的频段范围内。那就意味着更多的噪音源能够被衰减时,方向性就能实时地调整以提供来自前方信号的最大增益。
当这个多通道自动,自适应指向性助听器在噪声环境下增加言语可懂度方面提供了高层次的复杂性,但这个技术仍然有它的局限性。传统指向性麦克风的内在自然特性意味着噪音的衰减只能发生在用户背后的半球面积内,而且指向性只能指向佩戴助听器用户的前方。在助听器佩戴者面向其感兴趣的人的大部分环境里,这个功能是非常令人满意的。即使说话人在他们说话时不在助听器使用者的前方,助听器使用者也能转身面向说话人。
唯一的情况就是传统的指向性麦克风无法起作用,也就是说助听器佩戴者无法面对说话人。一个特殊情况,但也是非常普遍的,就是助听器佩戴者正开着车,并且乘客是在后方说话。在这种情况下,言语在后方,噪音在两边和前方,但助听器佩戴者在开车而不能转身面对说话者。另一个相似的情况就是助听器佩戴者和一群人肩并肩走路。在这种情况下,言语在两边,这个是指向性麦克风不能提供的地方,并且助听器佩戴者不能总是转向说话者。
理想型的麦克风系统应该能为言语提供最大的指向性,不论声音起源于哪个方向—即使声音起源于聆听者的后面。
一个新的“全向指向性”运算法则已经诞生了,它叫做言语环向追踪。言语环向追踪运算法则克服了传统指向性麦克风的局限,更多独特的极性图在某些聆听环境中被使用。除了具有四通道自适应指向性麦克风的功能外,当有需要时,言语环向追踪能自动地减弱来自佩戴者前方的噪声,并且集中从不同方向而来的言语声,比如来自佩戴者后方的声音。言语环向追踪不断地扫描聆听环婉中的言语声。言语一旦被侦测到,言语环向追踪选择能够集中言语信息最有效的方向性极性图,而且能够在没有噪音存在时洗择个向性。
言语环向追踪:工作原理
言语环向追踪可运行三种不同的指向性极性图:全向性,自适应指向性和相反的指向性〔倒心型)极性图。不像典型的指向性麦克风极性图(比如心形,超心形等),这些极性图只能削弱来自两边和后面的声音,后指向性麦克风极性图就像是声音的后视镜并且在噪声来自前半球时衰减噪声,集中来自后方的言语信息。
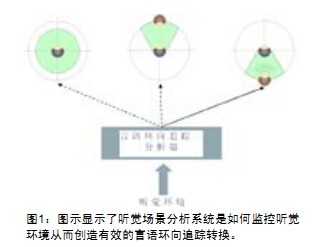
当言语存在时,并且背景噪声也被侦测到,从所有方向而来的信号均被分析成言语指向性(图1])。能够使言语信号得到最大输出的麦克风极性图被选择出来作为最合适的麦克风模型。这就意味着,当言语在前半球被侦测到时,传统的前方自适应指向性麦克风极性图启动,减少来自两边和后面的噪音。当侦测到言语来自后方时,后指向性麦克风极性图被选择,并且来自前半球的噪音被衰减。当言语被侦测到来自左边或者右边时,全指向性麦克风极性图就启动。因为这个只能在准确的+1-90.时发生,在自然世界中有噪音时,经常不是前方指向性就是后方指向性启动。
言语环向追踪的决策程序依靠于言语极性图的侦测,特别是人类言语声的调制。典型的言语调制频率大致接近于日Z,正确的言语至少需要拾取1秒以上的声音来分析。因此,言语环向追踪运算法则具有大约1秒的起效时间。换句话说,当言语被特殊的方向性拾取时,大约需要1秒的时间来选择合适的极性图。然而在一些聆听环境中,这个拾取时间可能对言语理解并不是足够快。因此,为了得到最大有效性,言语环向追踪应该在独立的程序中迄用,以得到静态的聆听环境,尤其预先知道言语将会来自聆听者的后方情形时使用,比如当开着车搭载着乘客时。
言语环向追踪只要背景噪声小于等于fi5d日SPL,就选择全向性指向性极性图。就像Branda和Hemandez描述的那样,在轻声聆听环境中,指向性也是有需求的,这个可用到传统的自动,自适应前指向性设置。因此,对于很多用户来讲,最有效的是使用标准自动1自适应指向性在常规程序中,言语环向追踪用在不同的程序中。
电声学分析
先前对言语环向追踪运算法则进行了行为学习,第一个电一声学分析由爱荷华大学进行以确保自动转换和自适应极性图的准确。以下的极性图实验结果是在消声室内由西门子飘701获得。
图2显示了言语在0度角的有75dBSPL(左〕响度,无噪音时的结果。结果是全向性极性图。在中间这个习里,显示了在后面180度角方位那增加了背景噪音(多人言语声〕的结果极性图。和我们预期的一样,前指向性心形图出现。最后,我们转换了言语和噪音的方位,所以言语来自后方,噪音来自前方。这个实验的结果显示了相反的极性图〔右〕。综上所述当选择言语环向追踪模式时,从本质上来说自动,自适应
指向性功能和标准常规的指向性模式是同样起作用的,除了增加了反一合形极性图的使用。
言语环向追踪的行为测试
为了检查言语环向追踪在背景噪声下提高言语理解力的有效性,在两个不同的地点进行了临床研究:地点1在爱荷华大学,地点2在北科罗拉多州大学。两个地方使用了相同实验方法。
受试者均是具有下降性感音神经性听力损失,且是有助听器使用经验的 {n二15地点1,n二21地点2)。受试者双耳佩戴了西门子飘701耳背机,而且使用了封闭式耳塞.使用CON N EXX软件对助听器进行编程,并且选择了NAL-NL1公式进行首次验配。使用真耳分析对助听器进行校准来确保达到目标增益;对增益和压缩进行微调以获得更精细的验配。处方增益和输出在助听器内以3种记忆存储。这3种记忆只有麦克风模式的不同,其他均相同:记忆t全向性,记忆2::传统的前自动,自适应指向性,记忆3:言语环向追踪〔自动1自适应指向性包含后指向性)。所有特殊的功能(比如噪音衰减,反馈抑制等)仍在所有麦克风模式中起作用。
测试声是个声音组合,言语从后方 (180.方位)传来,噪声从前方播放器(a.方位)传来。言语材料使用的是噪声中聆听材料(HINT),通过CD播放。标准的HIN丁材料被轻微地修改:句子中安静的问隔里有HIN丁的噪声,并且在每个句子前擂入一句短语“请重复下句句子”。标准的HIN丁噪声维持在72dB (A))水平,句子的响度水平是自动变化言语环向追踪的验配提示
在CONNExx软件中,言语环向追踪可作为一个独立的麦克风设置,并且是“言语环向追踪”程序的默认设置。我们建议言语环向追踪功能是为病人设置在程序中使用,只要声音来自其他的方位而不是来自前方,并且佩戴者不能面向说话者时可切换程序。
当病人使用言语环向追踪作为他们的主要程序时,在高水平噪声环境下这个运算法则会自动激活方向性,因此我们建议在每天的聆听环境中使用标准自动,自适应方向性模式。我们也建议固定全向性麦克风模式应用在音乐和室外程序,混合输入模式也一样,比如使用DA!或者Tek转换器。
言语环向追踪运算公式的功能能很容易地在Connexx软件中使用实时演示功能测试。这个为助听器验配师理解这个功能的操作是非常有用的,并且对终端用户的验配也是非常有效的。图6是"Connexx实时演示”显示的某个画面。这个特殊的记录能在噪声中言语环境中获得,并且言语来自于后方。
图6显示了助听器佩戴者面向前方的鸟瞰图。言语来自于哪个方向,绿色区域就指向这个方向。通过简单地举着助听器,并且说话或者模拟噪音在不同的方向,我们就能观察到这个运算法则的自动运转,因此我们观察到的自动切换情形和用户在真实世界中体验到的是一样的。
在验配过程中,助听器佩戴者能边听边看言语环向追踪的效果。以下是我们认为很成功的步骤:
双耳验配助听器并调试到需求的增益和输出
选择言语环向追踪设置
通过两个扬声器播放Connexx软件
中的声音文件。调整音量大小直至声音
维持在70dBSPL左右
首先,放置播放言语信号的扬声器在助听器佩戴者的前方,并且放置播放噪声的扬声器在佩戴者的后方。在这种聆听环境下,前指向性极性图将会显示,并且绿色区域将会在前方集中。
这时,调换扬声器的位置(或者旋转病人)以至于言语能从后方过来,噪声从前方进来。在这种聆听环境下,后指向性心形极性图将会激活并且绿色的区域将会出现在佩戴者的后方(如图6所示)
奋最终,移动言语声或噪声的扬声器到不同的位置来观察自动,自适应极性图的变化。
当方向性麦克风技术在助听器中使用超过40年时,应当有更重要的进步出现。直到现在,方向性技术不能非常成功的聆听环婉就是噪声中言语环境,而且言语是出现在聆听者的后方。西门子的言语环向追踪技术,包含了后指向性极性图,可用来提高在这种聆听环境下的言语理解力。
两个独立实验地点的临床研究,比较了言语环向追踪和两个可更换的麦克风选项:全向性和传统的前自适应指向性。这个结果显示了言语环向追踪在噪声中言语环境下理解言语具有明显优势。这个麦克风模式和全向性相比能多提供约5dB,和前自适应指向性相比能多提供约10dB。为了推进对言语环向追踪的理解,对于助听器验配师和病人来说,这个功能的“实时”表现能在Connexx软件中观察到.
就像在大多MarkeTrak报告中指出的那样,助听器的总体满意度经常和聆听环境的数量有关,在这些环境中,病人会指出助听器能提供帮助。有了言语环向追踪,我们相信会增加一个用户反映能明显提高言语理解力的聆听环境。